1. 인덱스도 특정 '자료 구조' 로 저장되는 데이터
DBMS에서 데이터베이스 테이블의 검색 속도를 높이기 위해 인덱스(Index)를 사용한다. 인덱스는 마치 책의 맨 뒤에 있는 '찾아보기(색인)'와 같은 역할을 하는 것이다. 책 전체를 처음부터 끝까지 읽지 않고도, 색인을 통해 원하는 내용을 빠르게 찾을 수 있는 것처럼, DBMS도 인덱스를 사용해 원하는 데이터가 어디에 있는지 효율적으로 찾아낸다.
어떻게?
인덱스를 새로 만든다고 하면, DBMS는 별도의 저장 공간을 마련해 특정 컬럼의 데이터와 그 데이터가 저장된 물리적 주소(위치 정보)를 특정 자료구조의 형태로 저장해 둔다. 이 별도의 저장 공간에 저장된 데이터들이 바로 인덱스다. (데이터 위치를 빠르게 찾을려면 인덱스가 특정 자료 구조로 저장되어 있어야만 함! 그 자료 구조가 대표적으로 B-Tree 또는 Hash인 것이다.)
DBMS마다 지원하는 인덱스 자료 구조(알고리즘)는 조금씩 다르며, 대부분의 DBMS는 여러 종류의 인덱스 알고리즘을 제공한다. 보통 기본값은 거의 다 B-Tree 계열인데, 특정 용도에 맞춰 Hash, GiST, GIN, R-Tree 같은 특수 인덱스를 추가 지원하기도 함. 대부분의 DBMS에서 인덱스 생성 시 사용자가 알고리즘을 지정하지 않으면 B-Tree가 기본값이며, 다른 알고리즘을 사용하려면 생성 시 직접 명시해 주면 된다.
[참고] 다양한 인덱스 자료구조(알고리즘)
B-Tree: 범위 검색, 정렬, 대부분의 WHERE 조건에 최적
Hash: = 정확 일치 검색에 최적, 범위 검색 불가
Fulltext: 자연어 검색, 전문 검색
R-Tree / GiST: 좌표, 지도, 공간 데이터
Bitmap: 카디널리티 낮은 컬럼(성별, 예/아니오)에 최적
사용자가 특정 데이터를 찾으려고 할 때, DBMS는 데이터가 저장된 테이블 전체를 처음부터 끝까지 스캔(Full Table Scan)하는 대신, 이 인덱스가 저장된 공간을 먼저 확인한다. → 인덱스는 이미 정렬되어 있으므로 이진 탐색과 같은 효율적인 방법으로 원하는 데이터의 위치(물리적 주소)를 빠르게 알아낼 수 있고 이렇게 얻은 주소를 이용해 → 곧바로 해당 데이터가 있는 곳으로 이동하여 데이터를 읽어오는 것.
결론적으로, 인덱스는 데이터 검색의 효율성을 극대화하여 1) 시스템의 부하를 줄이고 2) 쿼리 성능(속도)을 크게 향상시키는 중요한 역할을 한다.
2. 예시를 통해 인덱스를 이해해보자.
SELECT company_id
, units
, unit_cost
FROM index_test
WHERE company_id = 18
예를 들어 위와 같은 SQL 쿼리를 실행한다고 생각해보자.
만약 인덱스가 없다면 company_id가 18인 모든 경우를 찾기 위해 전체 테이블의 데이터를 하나씩 훑을 것이다. 테이블 크기가 커질수록 이 작업은 점점 더 많은 시간을 소모하게 될 것이다.
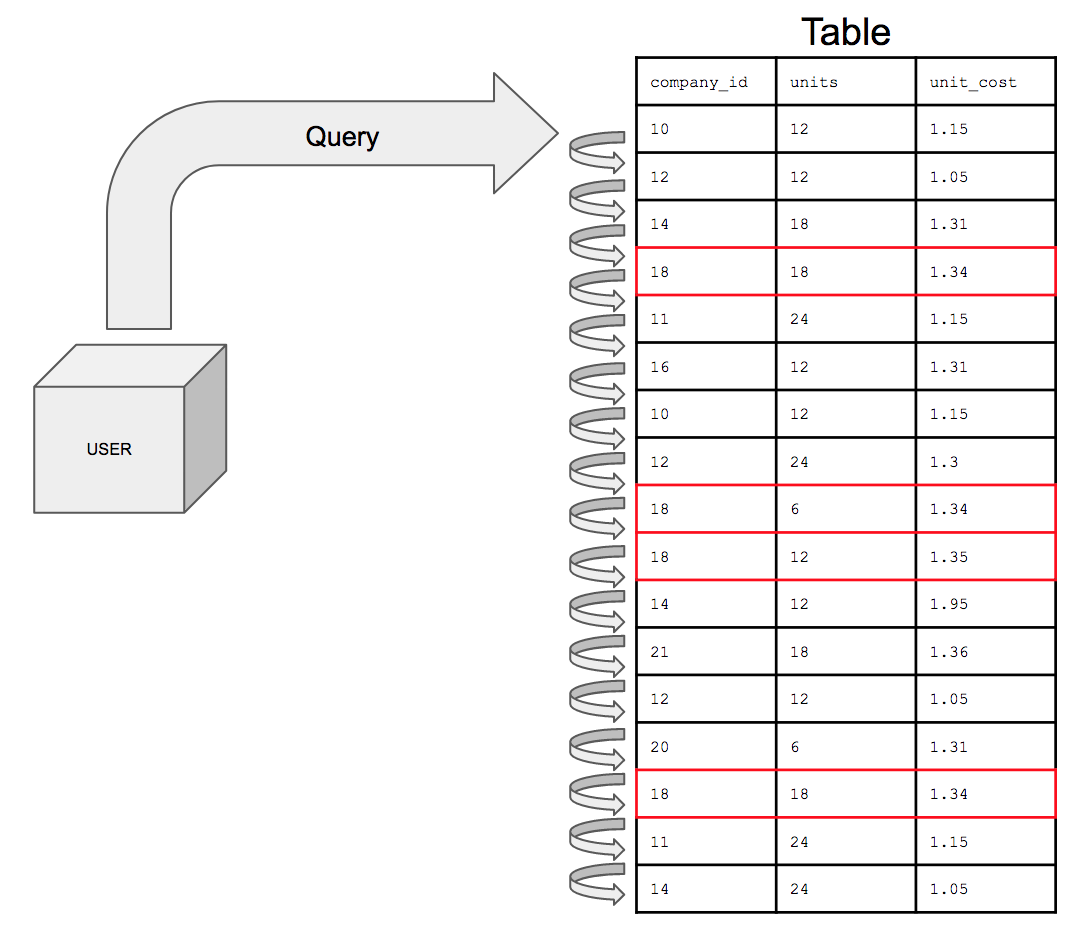
그런데 인덱스가 있다면 전체 테이블의 모든 데이터를 하나씩 훑지 않아도 된다. 인덱스를 사용하면 쿼리는 해당 열(company_id)에서 18이 있는 행만 검색한 후, 물리적 주소(위치 정보)인 포인터를 사용하여 테이블 내부로 이동하여 해당 포인터가 있는 특정 행을 빠르게 찾을 수 있다. 그런 다음 테이블 내부로 이동하여 조건을 충족하는 행에 대해 검색할 수 있는 것이다.
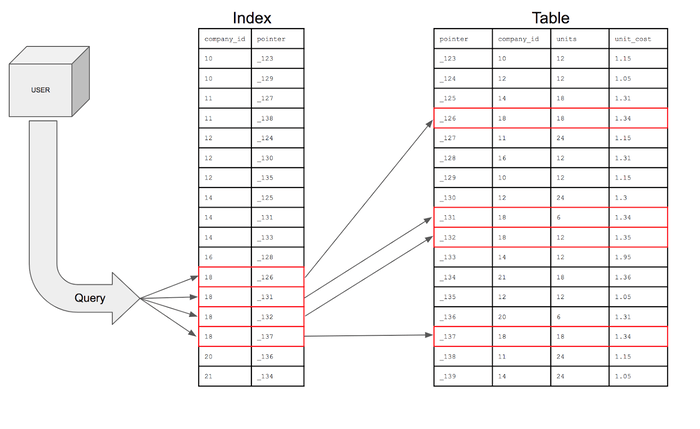
3. 인덱스의 자료 구조
(1) B-Tree 인덱스
- 대부분의 RDBMS에서 기본 인덱스 구조 (MySQL InnoDB, PostgreSQL, Oracle 등)
- 키 값이 정렬된 상태로 저장됨
- 범위 검색, 정렬, 최소/최대값 조회에 강함
- 특징: WHERE, ORDER BY, BETWEEN, <, > 같은 범위 조건 처리 가능
(2) Hash 인덱스
- 키 값을 해시 함수로 변환해 저장
- 값이 정렬되어 있지 않음
- 범위 검색 불가, 정확히 일치하는 검색(=)에 매우 빠름
- 예: (user_id) 해시 인덱스 → WHERE user_id = 100 같은 조건에서 초고속
정리
인덱스가 B-Tree나 해시 구조로 저장된다는 건,
인덱스를 구현할 때 B-Tree(정렬 기반)나 Hash(일치 검색 특화) 같은 자료구조를 사용한다는 뜻.
이 구조 덕분에 DB가 원하는 데이터를 훨씬 빠르게 찾을 수 있는 것이다.
'데이터 처리 도구 > SQL' 카테고리의 다른 글
| [빅쿼리(BigQuery)] JSON을 다루는 함수 (1) (0) | 2025.10.03 |
|---|---|
| [빅쿼리(BigQuery)] STRUCT, ARRAY 그리고 UNNEST 함수 (0) | 2025.09.22 |
| SQL 성능 향상을 위한 공부: 1-4) 실행 계획을 확인하는 방법 (0) | 2025.07.21 |
| SQL에서 날짜 데이터 타입 차이 (DATETIME vs. TIMESTAMP) (0) | 2025.07.17 |
| SQL 성능 향상을 위한 공부: 1-3) 쿼리 평가엔진에 대하여 (0) | 2025.07.11 |