- 빅쿼리(BigQuery)의 JSON 데이터 타입은 내부적으로 최적화된 바이너리 포맷으로 저장되기 때문에, 키(key)의 순서를 보장하지 않음. 빅쿼리는 JSON을 입력받으면 이를 정규화(Canonicalization) 과정을 거쳐 바이너리 포맷(Capacitor)으로 변환한다.
- JSON 객체로 저장된 값을 추출할 때, 특정 키에 매칭하는 값 하나만 가져오는 경우는 상관 없지만, JSON 객체에 여러 "키:값"이 존재하며 이걸 통으로 추출해야 할 때 문제가 생길 수 있음.
- 예를 들어 TO_JSON_STRING 함수를 사용하여 JSON 객체로 저장된 데이터를 A JSON-formatted 문자열로 추출한다고 해보자. 이 함수는 현재 상태의 JSON을 그대로 문자열로 변환할 뿐, 변환 과정에서 키를 정렬해주는 옵션을 제공하지 않는다. 따라서 내용은 같은데 키의 순서만 다른 경우 이를 그대로 문자열로 변환하면 결국 다른 문자열 값으로 변환되게 됨. 아래 예시처럼 키와 값의 내용은 모두 같은데 키 이름의 순서가 다르게 추출된 상태에서 문자열로 변환되면 다른 문자열 값이 되는 것.
{"apple": 10, "banana": 3, "cherry": 5}
{"banana": 3, "apple": 10, "cherry": 5}
- 참고로 키만 추출할 때는 그래도 비교적 쉽게 정렬이 가능했음. (JSON_KEYS 함수를 통해 키만 추출하는데 배열로 리턴되기 때문에 UNNEST로 각 행으로 펼친 후 정렬을 할 수 있고 그 다음 그 값들을 다시 ARRAY로 묶을 수 있음) 근데 키와 값을 다 가져올 때는 키 기준으로 키와 값이 같이 정렬되어야 하기 때문에 조금 더 과정이 추가될 수 있으나 이 방법을 활용하여 가능함.
(키를 알파벳 순으로 정렬하여 일관된 문자열을 얻으려면 UDF(User Defined Function)를 사용하는 것이 가장 확실한 방법이라고 함. GPT와 제미나이 둘다 같은 답변을 해줌. 단, UDF는 대용량 데이터(수십억 건 이상) 처리 시 네이티브 함수보다 성능이 느릴 수 있다고 함. 검색 성능이 중요하다면, 데이터를 테이블에 저장할 때 미리 정렬된 상태의 문자열 컬럼을 별도로 만들어 두는 것도 좋은 방법이라고 제미나이가 추천해줌.)
키 정렬하여 키만 추출하는 방법
SELECT event_name
, ARRAY_LENGTH(JSON_KEYS(event_properties)) AS cnt_keys -- event_properties의 키 개수
, ARRAY(SELECT key_name FROM UNNEST(JSON_KEYS(event_properties)) AS key_name ORDER BY key_name) AS key_name -- event_properties의 키 이름 (키 이름을 정렬하기 위해 JSON_KEYS한 결과를 UNNEST하여 ORDER BY로 정렬한 후 다시 ARRAY로 만듦)
FROM events_data
키 기준으로 정렬하여 '키:값' 모두 추출하는 방법
<쿼리 작동 원리>
'객체' 형태인 JSON을 '표(Table)' 형태로 완전히 분해했다가, 원하는 순서로 다시 조립하는 것.
WITH raw_data AS (
-- 테스트용 데이터 (순서가 제각각인 JSON)
SELECT 1 AS id, JSON '{"banana": 3, "apple": 10, "cherry": 5}' AS event_properties
UNION ALL
SELECT 2 AS id, JSON '{"z": 100, "a": 50, "m": 70}' AS event_properties
)
SELECT id
, CONCAT('{', STRING_AGG(FORMAT('"%s":%s', k, v), ',' ORDER BY k), '}') AS sorted_event_properties -- STEP 4. 최종적으로 다시 { }를 붙여 JSON 문자열 완성
FROM (
SELECT id
, k
, TO_JSON_STRING(event_properties[k]) AS v -- STEP 2. 각 키에 해당하는 값을 추출
FROM raw_data
CROSS JOIN UNNEST(JSON_KEYS(event_properties)) AS k -- STEP 1. JSON 키들을 펼침
)
GROUP BY id -- STEP 3. ID별로 그룹화하여 키 순서대로 다시 합침
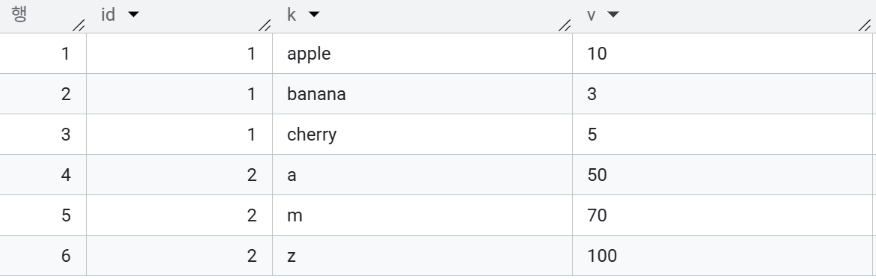
1단계: JSON 키를 추출한 후 행으로 펼치기 (UNNEST)
(1) JSON_KEYS(event_properties) 함수를 통해 JSON 객체에 포함된 모든 키(key)를 배열(['banana', 'apple', 'cherry'])로 뽑는다.
(2) 배열 형태의 키들을 각각의 행(row)으로 펼친다. 이제 하나의 JSON 데이터는 키의 개수만큼 여러 행으로 펼쳐진다.
2단계: 값 매칭 (event_properties[k])
펼쳐진 각 키(k)를 인덱스로 사용하여 원래 JSON에서 해당 값(v)을 찾아온다. 이때 TO_JSON_STRING을 사용하면 값이 문자열이면 "value", 숫자면 123 그대로의 형식을 유지하며 문자열로 변환한다.
<주의사항>
1. JSON_VALUE 는 사용하면 안됨
- JSON_VALUE를 사용하면 값이 문자열일 경우 따옴표(")가 제거되어 나중에 유효한 JSON 문자열을 만들 때 문제가 생길 수 있음. => "apple":red (X)
- 반면 TO_JSON_STRING을 쓰면 값의 타입을 유지한 채 문자열화 해줌. => "apple":"red" (O)
2. JSON_QUERY는 사용하게 되면 오류가 남
- JSON_QUERY를 사용하면 "Invalid type for argument 3 to FORMAT; Expected STRING; Got JSON" 이런 오류 메시지와 함께 쿼리 실행이 안됨. 왜냐하면
- JSON_QUERY 함수의 반환값은 문자열이 아니라 JSON 데이터 타입 그 자체다.
- 근데 FORMAT 함수의 '%s' 이 지정자는 STRING 타입을 기대한다. (숫자나 날짜는 자동으로 문자로 바꿔주지만, JSON 타입은 보안이나 복잡성 문제로 자동 변환을 허용하지 않는다고 함.)
- 그래서 다음 단계에서 FORMAT('"%s":%s', k, JSON_QUERY(...))라고 쓰여진 셈이 되는데, 이때 세 번째 인자인 JSON 데이터를 %s가 처리하지 못해 "Expected STRING; Got JSON"이라는 오류를 뱉게 되는 것.
- 해결 방법:
1) FORMAT 함수의 지정자를 %j로 변경하기 (만약 JSON_QUERY 결과(JSON 타입)를 그대로 FORMAT 함수에 넣고 싶다면, %s 대신 JSON 전용 지정자인 %j를 사용해야 함.)
2) JSON_QUERY 대신 TO_JSON_STRING 함수를 사용하기 (TO_JSON_STRING 함수는 입력받은 JSON을 미리 STRING 타입으로 변환해서 내보낸다. 따라서 FORMAT 함수의 %s 입장에서는 이미 '문자열'이 들어온 것이므로 아무 문제 없이 작동함) => 우린 이 방법을 선택한 것!
3단계: 정렬 및 재조립 (STRING_AGG with ORDER BY)
- GROUP BY id를 통해 다시 하나의 데이터로 모으면서, STRING_AGG 함수 내부의 ORDER BY k 옵션을 사용해 키(k)를 알파벳 순서로 정렬하며 이어 붙인다.
- 이어 붙이기 전에 먼저 분리되어 있는 k와 v을 JSON 객체 포맷과 동일하게 키와 값이 매칭된 "k":v 형태로 만들어줘야 한다. 이때 FORMAT함수를 사용한다.
4단계: JSON 구조 완성 (CONCAT)
앞뒤에 대괄호 '{', '}' 를 붙여 최종적으로 정렬된 JSON 형태의 문자열을 완성한다.
OUTPUT:

[참고] raw_data만 조회해도 사실 이렇게 키 기준으로 값이 정렬된 결과가 나옴.
WITH raw_data AS (
-- 테스트용 데이터 (순서가 제각각인 JSON)
SELECT 1 AS id, JSON '{"banana": 3, "apple": 10, "cherry": 5}' AS event_properties
UNION ALL
SELECT 2 AS id, JSON '{"z": 100, "a": 50, "m": 70}' AS event_properties
)
SELECT *
FROM raw_data
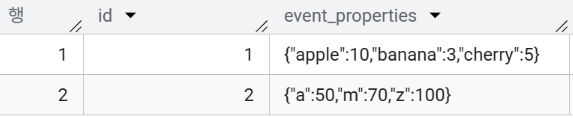
빅쿼리 콘솔에서 JSON 데이터 타입을 조회하면 마치 키 순서가 보장되는 것처럼 깔끔하게 정렬되어 보인다.
실제 테이블에 저장된 데이터를 SELECT *로 불러와도 정렬되어 보이는 이유는 크게 두 가지로 추측.정확한 내용을 더 조사해 봐야함.
1) 정규화된 직렬화 (Canonical Serialization): 빅쿼리 엔진이 바이너리로 저장된 JSON을 다시 텍스트(문자열)로 변환해 사용자에게 줄 때, 일관성을 위해 키를 정렬된 순서로 내보내는 내부 규칙이 있을 수 있음.
2) UI 렌더링: 사용자가 보고 있는 빅쿼리 콘솔(웹 화면) 자체가 JSON 데이터를 받아서 화면에 그릴 때, 브라우저나 콘솔 엔진 단에서 키를 정렬하여 보여주는 'Prettify' 기능을 수행하기도 함.
하지만 중요한 것은 실제 저장 방식은 순서를 보장하지 않으며, 데이터가 커지거나 시스템 환경이 바뀌면 순서는 언제든 뒤바뀔 수 있다는 것. 특히 JSON 데이터를 문자열(String)로 비교할 때는 두 데이터를 모두 키 순서로 정렬한 문자열로 만든 뒤 비교해야 정확하다. JSON 타입끼리는 직접 비교(=)가 안 되기 때문에 보통 TO_JSON_STRING으로 바꿔서 비교해야 하는데, 이때 순서가 다르면 분명히 똑같은 데이터인데 FALSE가 반환되는 대참사가 발생하기 때문. 안전하게 정렬한 후 진행하자!
'데이터 처리 도구 > SQL' 카테고리의 다른 글
| [빅쿼리(BigQuery)] 문자열에 MAX() 함수를 쓰면 어떻게 될까? (feat. NULL 처리) (0) | 2026.01.10 |
|---|---|
| [빅쿼리(BigQuery)] JSON 데이터 타입 다루기 (4) TO_JSON_STRING 함수 (0) | 2025.12.30 |
| [빅쿼리(BigQuery)] JSON을 다루는 함수(2) TO_JSON_STRING 함수 (모든 컬럼 값이 100% 중복인 행 찾는 방법) (0) | 2025.12.23 |
| [빅쿼리(BigQuery)] STRING_AGG 문자열 연결하는 집계함수 (0) | 2025.12.16 |
| [MySQL] CAST 함수 (0) | 2025.12.02 |