윈도우 함수
- 윈도우 함수란, 행(row) 집합을 대상으로 계산하는 함수다.
- 따라서 윈도우 함수를 사용하면 행과 행간의 관계를 쉽게 정의할 수 있다.
- 행 집합 단위로 계산한다는 점에서 'GROUP BY + 집계 함수'를 사용하는 것 비슷하지만 다르다.
'GROUP BY + 집계 함수' vs. 'Window Functions + 집계 함수'
- GROUP BY + 집계 함수는 해당 되는 행(row) 집합에 대해서 단일 행으로 그룹화하여 쿼리 결과를 보여주지만, 윈도우 함수는 쿼리 결과를 각 행에 대해 생성한다. 따라서 윈도우 함수를 사용하면 행의 수가 그대로 유지된다.
- GROUP BY 와 함께 사용하는 집계 함수들은 대부분 윈도우 함수에서도 사용 가능하고, 집계 함수는 아니지만 윈도우 함수에서만 사용할 수 있는 특정 함수들이 있다.
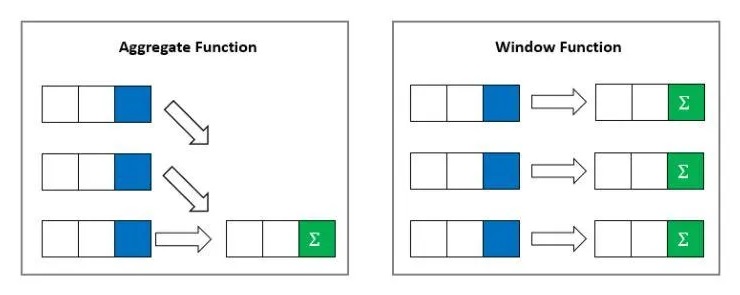
-- 모양새
함수(컬럼) OVER(PARTITION BY 컬럼 ORDER BY 컬럼)함수
- GROUP BY 와 함께 사용할 수 있는 집계 함수 (MAX, SUM, COUNT 등)
- 윈도우 함수에서만 사용할 수 있는 특정 함수 (ROW_NUMBER 등)
OVER
- 윈도우 함수 사용시 꼭 작성해야하는 부분이다.
- OVER 안에 PARTITION BY 나 ORDER BY 를 둘 다 필수로 작성할 필요는 없다. 원하는 결과에 따라서 필요에 따라 작성하면 된다.
- PARTITION BY 는 GROUP BY 와 비슷하다. 어떤 컬럼을 기준으로 나눌지에 대한 부분으로 컬럼명을 작성하면 된다.
- ORDER BY 는 어떤 컬럼을 기준으로 순서를 정할지에 대한 부분으로 컬럼명을 작성하면 된다.
활용 1. 윈도우 함수로 집계하기
GROUP BY 와 함께 사용하는 집계함수들 중에서 윈도우 함수로 사용할 수 있는 함수들이 있다. 아래는 윈도우함수로 사용할 수 있는 집계함수들이다.

[새로 알게된 점]
COUNT함수를 OVER절과 함께 윈도우 함수로 사용할 때는, DISTINCT를 사용할 수 없다. 그 이유는 'SQL 표준'에서 DISTINCT가 포함된 집계 함수가 윈도우 함수로 작동하는 것을 허용하지 않아서. (DISTINCT와 윈도우 함수의 결합을 지원하지 않도록 정의되어 있기 때문이라고 한다). 이로 인해, COUNT(DISTINCT column)와 같은 표현을 윈도우 함수에서 사용할 수 없다. 이를 준수하는 다른 RDBMS에서도 동일한 제한이 적용된다.
✏️ 예시
-- 모양새
MAX(컬럼) OVER(PARTITION BY 컬럼)
-- 예제: 부서별 가장 높은 임금?
SELECT emp_id
, emp_name
, dept_id
, position
, sal
, Max(sal) OVER(PARTITION BY dept_id) AS max_sal
FROM emp
| emp_id | emp_name | dept_id | position | sal | max_sal |
| 1 | Amy | d1 | manager | 200 | 200 |
| 2 | Ben | d1 | staff | 100 | 200 |
| 3 | Cindy | d2 | manager | 300 | 300 |
| 4 | Danny | d2 | staff | 200 | 300 |
| 5 | Eric | d1 | staff | 150 | 200 |
활용 2. 누적합 구하기
SUM() 함수를 윈도우 함수로 사용하면, 특정 순서대로 행을 누적하여 합한 결과를 행마다 표시할 수 있다.
✏️ 예시
-- 모양새
SUM(컬럼) OVER(ORDER BY 컬럼)
-- 예제: 물고기가 잡힌 순서대로 가격 누적합?
SELECT id
, date
, fish_id
, fish_name
, price
, SUM(price) OVER(ORDER BY date) AS cum_sum
FROM fish
| id | date | fish_id | fish_name | price | cum_sum |
| 1 | 2020-01-01 | a001 | rockfish | 20,000 | 20,000 |
| 2 | 2020-01-02 | a001 | rockfish | 20,000 | 40,000 |
| 3 | 2020-01-03 | a002 | yellowtail | 30,000 | 70,000 |
| 4 | 2020-01-05 | a001 | rockfish | 20,000 | 90,000 |
| 5 | 2020-01-07 | a003 | snapper | 40,000 | 130,000 |
활용 3. 순위 정하기
윈도우 함수로만 사용되는 비집계 함수들도 있다. 대표적으로 순위를 정하는 함수들이 있다.
1. ROW_NUMBER( ), RANK( ), DENSE_RANK( )
: 모두 괄호안에 인자를 작성하지 않는다. 순위를 계산할 기준은 OVER 안에 있는 ORDER BY 에 작성한다.
- ROW_NUMBER( ) : 중복 순위 허용 X
- RANK( ) : 중복 순위는 허용하지만, 중복 순위를 갖는 갯수의 다음 숫자부터 순위를 매긴다. 1등이 두명이면 2등은 없고 다음 등수는 3등이다.
- DENSE_RANK( ) : 중복 순위를 허용하지만, 중복 순위를 갖는 갯수와 상관없이 모든 숫자를 사용하여 순위를 매긴다. 1등이 두명이든 세명이든 상관없이, 다음 등수는 2등부터 시작한다.
- PERCENT_RANK( ) : 0부터 1까지의 값으로 백분위를 매긴다. (rank - 1) / (total rows - 1). 첫번째 행은 0 마지막 행은 1. 중복 값의 경우 동일한 RANK를 가지므로, PERCENT_RANK도 동일하게 계산됨.
2. NTILE( ) : 데이터 세트를 지정한 수의 그룹으로 나누고 각 행에 그룹 번호를 할당하다. 괄호 안에는 몇 개의 그룹으로 나눌 것인지 숫자를 작성한다. 이 함수는 데이터 분포를 고르게 나누고자 할 때 유용하다.
✏️ 예시
-- 예제
SELECT val
, ROW_NUMBER() OVER(ORDER BY val) AS 'row_number'
, RANK() OVER(ORDER BY val) AS 'rank'
, DENSE_RANK() OVER(ORDER BY val) AS 'dense_rank'
, PERCENT_RANK() OVER(ORDER BY val) AS 'percent_rank'
, NTILE(4) OVER(ORDER BY val) AS 'ntile_4'
FROM numbers
| val | row_number | rank | dense_rank | percent_rank | ntile_4 |
| 1 | 1 | 1 | 1 | (1-1)/7 = 0 | 1 |
| 1 | 2 | 1 | 1 | (1-1)/7 = 0 | 1 |
| 2 | 3 | 3 | 2 | (3-1)/7 = 0.2857 | 2 |
| 3 | 4 | 4 | 3 | (4-1)/7 = 0.4286 | 2 |
| 3 | 5 | 4 | 3 | (4-1)/7 = 0.4286 | 3 |
| 3 | 6 | 4 | 3 | (4-1)/7 = 0.4286 | 3 |
| 4 | 7 | 7 | 4 | (7-1)/7 = 0.8571 | 4 |
| 5 | 8 | 8 | 5 | (8-1)/7 = 1 | 4 |
활용 4. 데이터 위치 바꾸기
데이터 위치를 바꾸는 함수도 OVER절과 함께 윈도우 함수로만 사용된다. OVER절없이 단독으로 사용할 수 없다.
1. LAG( ) : 파티션 안에서 현재 행 데이터를 뒤로 밀어내기
2. LEAD( ) : 파티션 안에서 현재 행 데이터를 앞으로 당겨오기
-- 모양새 (default values: offset = 1, default = NULL)
-- 이동 1칸씩, 빈값 NULL
LAG(컬럼) OVER(PARTITION BY 컬럼 ORDER BY 컬럼)
LEAD(컬럼) OVER(PARTITION BY 컬럼 ORDER BY 컬럼)
-- 이동 N칸씩, 빈값 NULL
LAG(컬럼, 오프셋 칸수) OVER(PARTITION BY 컬럼 ORDER BY 컬럼)
LEAD(컬럼, 오프셋 칸수) OVER(PARTITION BY 컬럼 ORDER BY 컬럼)
-- 이동 N칸씩, 빈값 지정
LAG(컬럼, 오프셋 칸수, Default) OVER(PARTITION BY 컬럼 ORDER BY 컬럼)
LEAD(컬럼, 오프셋 칸수, Default) OVER(PARTITION BY 컬럼 ORDER BY 컬럼)LAG( ) 와 LEAD( ) 둘 다 OVER 안에 ORDER BY는 필수로 작성해야 한다. 윈도우 함수는 행 간의 상대적 위치를 기반으로 작동하기 때문에, 이를 지정하지 않으면 함수는 어떻게 작동해야 할지 알 수 없기 때문이다. PARTITION BY는 데이터를 그룹으로 나누는 역할을 하며, 지정하지 않으면 전체 데이터 집합이 하나의 파티션으로 간주되므로 필요에 따라 옵셔널하게 작성하면 된다.
✏️ 예시
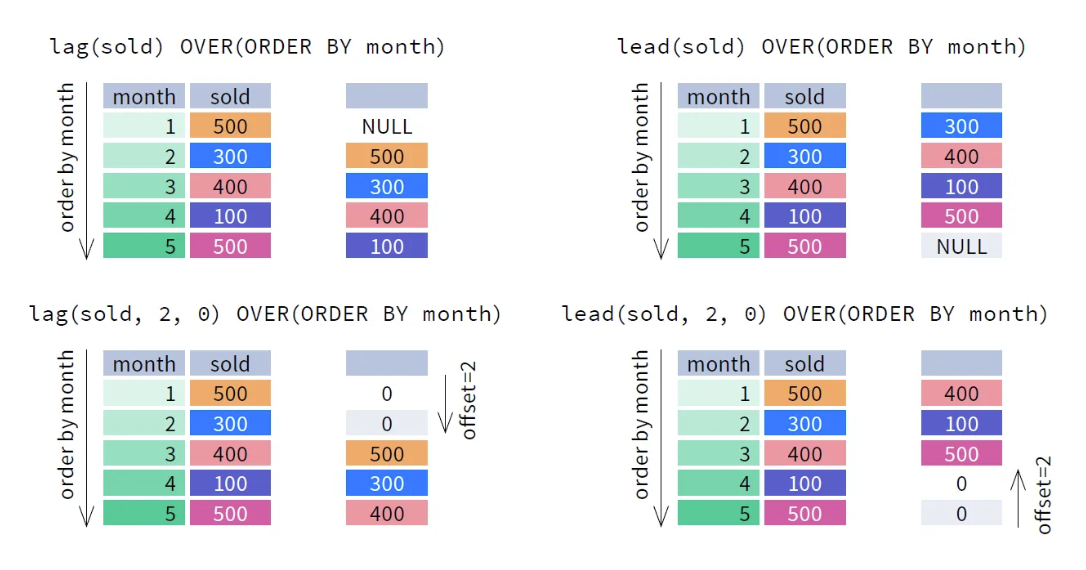
[참고자료]
https://schatz37.tistory.com/12
[SQL] 윈도우 함수(Window Function)의 소중함을 느껴보자
0. 들어가며 요즘에는 대부분의 DBMS에서는 윈도우 함수(Window Function)를 제공하고 있습니다. 업무를 하다보면 여러 서브쿼리를 이용하여 만들어야 할 결과물을 윈도우 함수를 활용해 아주 간단하
schatz37.tistory.com
https://learnsql.com/blog/sql-window-functions-cheat-sheet/
SQL Window Functions Cheat Sheet
This 2-page SQL Window Functions Cheat Sheet covers the syntax of window functions and a list of window functions. Download it in PDF or PNG format.
learnsql.com
MySQL Documentation > Window Function Descriptions
https://dev.mysql.com/doc/refman/8.4/en/window-function-descriptions.html
MySQL :: MySQL 8.4 Reference Manual :: 14.20.1 Window Function Descriptions
14.20.1 Window Function Descriptions This section describes nonaggregate window functions that, for each row from a query, perform a calculation using rows related to that row. Most aggregate functions also can be used as window functions; see Section 14
dev.mysql.com
'데이터 처리 도구 > SQL' 카테고리의 다른 글
| [MySQL] 비트 연산과 관련 함수(CONV, BIN, BIT_LENGTH) (0) | 2022.09.04 |
|---|---|
| [MySQL] 날짜/시간 다루기 (2) 연산하기 (0) | 2022.08.30 |
| [MySQL] JOIN (0) | 2022.08.28 |
| [MySQL] String Functions and Operators (2) (0) | 2022.08.27 |
| [MySQL] String Functions and Operators (1) (0) | 2022.08.26 |