문자열 나누기, 분리하기
1) Split
bread = "my favorite bread is Kouign-amann"
bread.split()
# OUTPUT: ['my', 'favorite', 'bread', 'is', 'Kouign-amann']
metro = "jongro-euljiro-chungmuro"
metro.split("-")
# OUTPUT: ['jongro', 'euljiro', 'chungmuro']- 문자열 나누기, 문자열 분리하기 함수
- bread.split( ) 와 같이 괄호 안에 아무것도 넣지 않으면, 공백 기준으로 문자열을 분리한다.
- metro.split("-") 와 같이 괄호 안에 특정 값을 넣으면, 해당 값을 구분자로 문자열을 분리한다.
- 분리된 결과 값은 리스트 안에 요소로 하나씩 들어가게 된다.
문자열 더하기, 합치기
1) + 부호 사용
head = "Love"
tail = " yourself!"
head + tail
# OUTPUT: 'Love yourself!'
2) Join
word = 'aeiou'
joined = ",".join(word)
print(joined)
# OUTPUT: "a,e,i,o,u"
s1 = ['my', 'favorite', 'food', 'is', 'bibimbap']
j1 = "-".join(s1)
print(j1)
# OUTPUT: "my-favorite-food-is-bibimbap"
s2 = ['I', 'love', 'my', 'job']
j2 = " ".join(s2)
print(j2)
# OUTPUT: "I love my job"- ",".join('aeiou') 와 같이 문자열에 적용하면, 각 문자 사이에 구분자를 넣어준다.
- " ".join(['I', 'love', 'my', 'job']) 와 같이 리스트에 적용하면, 리스트의 각 요소 사이에 구분자를 넣어서 하나의 문자열로 만들어준다.
데이터 프레임 합치기
1) Concat
import pandas as pd
df1 = pd.DataFrame([['ax','ay'],['bx','by']], index=['A','B'], columns=['X','Y'])
df2 = pd.DataFrame([['ax','az'],['cx','cz']], index=['A','C'], columns=['X','Z'])df1
| X | Y | |
| A | ax | ay |
| B | bx | by |
df2
| X | Z | |
| A | ax | az |
| C | cx | cz |
pd.concat([df1, df2]) # axis = 0 (default)
pd.concat([df1, df2], axis=1) # axis = 1axis = 0 → 세로로 붙이기
| X | Y | Z | |
| A | ax | ay | NaN |
| B | bx | by | NaN |
| A | ax | NaN | az |
| C | cx | NaN | cz |
axis = 1 → 가로로 붙이기
| X | Y | X | Z | |
| A | ax | ay | ax | az |
| B | bx | by | NaN | NaN |
| C | NaN | NaN | cx | cz |
- 붙인다. 잇는다. 이런 의미로 생각하기.
- 합하는 두 데이터 프레임의 컬럼 이름이나 인덱스 값이 일치해야한다. 그렇지 않은 경우, 비어있는 부분은 NaN 으로 채워진다.
- 아무 옵션을 적용하지 않으면 디폴트 값으로 join = 'outer', axis = 0 을 기준으로 합쳐진다.
<파라미터>
• Object: a sequence or mapping of Series or DataFrame objects
• axis = 0 or 1 (0:index, 1:columns), default 0
• join = ‘inner’ or ‘outer’, default ‘outer’
• ignore_index = True or False, default False
True로 하면 원래의 인덱스를 가져오지 않고 새로운 인덱스 넘버로 리셋해줌
• keys: sequence, default None
• levels: list of sequences, default None
• names: list, default None
• verify_integrity = True or False, default False
• sort = True or False, default False
• copy = True or False, default True
2) Merge
pd.merge(df1, df2) # how = 'inner' (default)
pd.merge(df1, df2, how='outer') # how = 'outer'how = 'inner'
| X | Y | Z | |
| A | ax | ay | az |
how = 'outer'
| X | Y | Z | |
| A | ax | ay | az |
| B | bx | by | NaN |
| C | cx | NaN | cz |
- concat 과는 다르게 아무 옵션을 적용하지 않으면 디폴트 값으로 how = 'inner' 기준으로 합쳐진다.
- on = "기준 컬럼" 적어주면 된다.
- on = None 이면서 인덱스를 기준으로 merge하지 않는 경우, 두 데이터프레임에 공통으로 존재하는 컬럼들을 기준으로 데이터의 교집합을 출력한다.
import pandas as pd
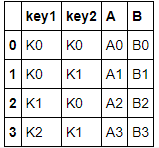
df3 = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
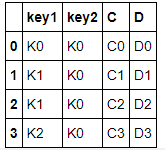
df4 = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
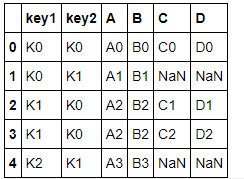
df34 = df3.merge(df4, how='left', on=['key1','key2'])
df34df3
df4
df34
[참고] merge how인자 방법
데이터 프레임 행/열 삭제하기, 제거하기
1) Drop
# index 0인 row(행) 제거
df.drop(0)
# index 0인 column(열)제거
df.drop(df.columns[0], axis=1)
데이터 프레임 인덱스 설정하기, 리셋하기
1) DataFrame 이 갖고있는 index, column 어트리뷰트를 통해 직접 배정
import pandas as pd
import numpy as np
df100 = pd.DataFrame(np.arange(0,9).reshape(3,3))
# df100
# 0 1 2
# 0 0 1 2
# 1 3 4 5
# 2 6 7 8
df100.index = ['r0', 'r1', 'r2'] # DataFrame.index = [ ]
df100.column = ['c0', 'c1', 'c2'] # DataFrame.column = [ ]
df100df100
| c0 | c1 | c2 | |
| r0 | 0 | 1 | 2 |
| r1 | 3 | 4 | 5 |
| r2 | 6 | 7 | 8 |
2) set_index 메서드를 사용하여 데이터 프레임의 특정 열을 인덱스로 설정하기
df200 = pd.DataFrame([[0, 1, 2, 'r0']
, [3, 4, 5, 'r1']
, [6, 7, 8, 'r2']]
, columns=['c0', 'c1', 'c2', 'id'])
# df200
# c0 c1 c2 id
# 0 0 1 2 r0
# 1 3 4 5 r1
# 2 6 7 8 r2
df200.set_index('id') # set_index(keys, drop=True, append=False, inplace=False)
df200df200
| c0 | c1 | c2 | |
| id | |||
| r0 | 0 | 1 | 2 |
| r1 | 3 | 4 | 5 |
| r2 | 6 | 7 | 8 |
3) reset_index 메서드를 사용하여 새로운 정수로 인덱스를 리셋하기
df200.reset_index(drop=True, inplace=True) # reset_index(level=None, drop=False, inplace=False)
df200df200
| c0 | c1 | c2 | |
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
- 기존 사용하던 데이터 프레임에 인덱스 리셋을 바로 적용하려면, reset_index( ) 는 drop 과 inplace 파라미터의 기본값이 False 이기 때문에 모두 True 로 바꿔주어야한다.
데이터 프레임 형태 바꾸기 (Reshape)
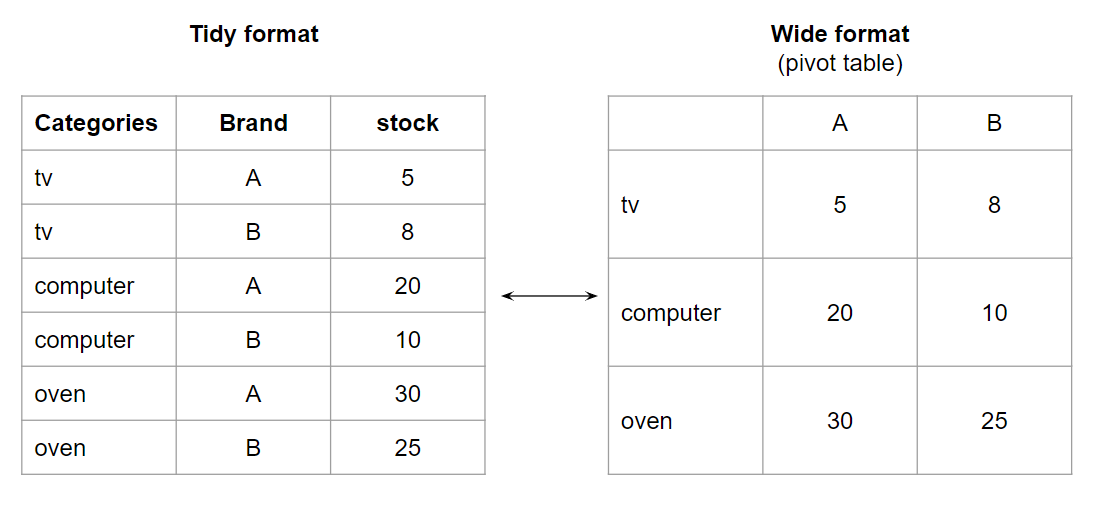
1) pivot_table( )
Tidy → Wide
df_wide = df_tidy.pivot_table(index='Categories', columns='Brand', values='stock')
df_wide
2) melt( )
Wide → Tidy
df_tidy = df_wide.melt(id_vars='Categories', value_vars=['A', 'B'])
df_tidy
파이썬 코딩 연습하기💬
🔽 데이터프레임 선택하기
'http://www.aaa.com/stocks/co1.csv'
'http://www.aaa.com/stocks/co2.csv'
'http://www.aaa.com/stocks/co3.csv'
위와 같이 여러 URL을 통해 데이터를 가져오는데, URL 앞부분은 같고 뒤에 파일명만 다른 경우 함수를 만들어서 쉽게 불러올 수 있다.
url_head='http://www.aaa.com/stocks/'
# 1. 함수 정의
def mydf(myurl):
df = pd.read_csv(url_head + myurl)
return df
# 2. 정의한 함수에 파일명만 넣기
df1 = mydf('co1.csv')
df2 = mydf('co2.csv')
df3 = mydf('co3.csv')
🔽 각 csv 데이터를 불러와서 첫번째 행을 헤더로 지정한 뒤, 모든 데이터 합치기
함수 만드는 방법 1
import pandas as pd
url_head = 'https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/stocks/'
def mydf(myurl):
df = pd.read_csv(url_head + myurl).transpose()
new_header = df.iloc[0]
df = df[1:]
df.columns = new_header
return df함수 만드는 방법 2
def mydf(myurl):
df = pd.read_csv(url_head + myurl, index_col=0).transpose()
return df
위에서 만든 함수를 적용한뒤 데이터 합치기
df = pd.concat([
mydf('co1.csv'),
mydf('co2.csv'),
mydf('co3.csv')])
🔽 Unnamed: 0 으로 되어 있는 컬럼(=헤더) 수정해주기
df_example = df_example.rename(
columns={'index':'IdNum'
,'Unnamed: 0':'Product'
,'value':'Value'}
)
🔽 콜랩에서 시각화도구 한글화 패치 방법
1. 아래 코드 실행
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf2. '런타임 다시시작' 후, 아래 코드 실행
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
🔽 특정 컬럼 기준으로 box plot 그리기
import seaborn as sns
sns.boxplot(data = df_example, x = 'Product', y = 'Value');
'코드스테이츠 AI 부트캠프 > Section 1' 카테고리의 다른 글
| AIB_121_복습정리 : Introduction to Data Science (1) (0) | 2021.09.26 |
|---|---|
| [비공개] AIB_11x : 1주차 Challenge (0) | 2021.09.26 |
| [비공개] AIB_114_복습정리 : Derivative(미분) (0) | 2021.09.26 |
| AIB_112_복습정리 : Feature Engineering (0) | 2021.09.15 |
| AIB_111_복습정리 : EDA, 데이터 전처리 (0) | 2021.09.15 |